软件工具 - Umi-OCR_v2.1.5
OCR,全称 Optical Character Recognition,翻译过来叫“光学字符识别”,大家更习惯叫它“文字识别”。有时候我们想复制文档里的文字,结果发现是扫描图或者图片,这时候就轮到 OCR 出场了。之前我写过一篇文章,推荐过几款需要联网才能用的 OCR 工具。今天要说的这款不太一样——它开源、免费、完全离线,名字叫 Umi-OCR。
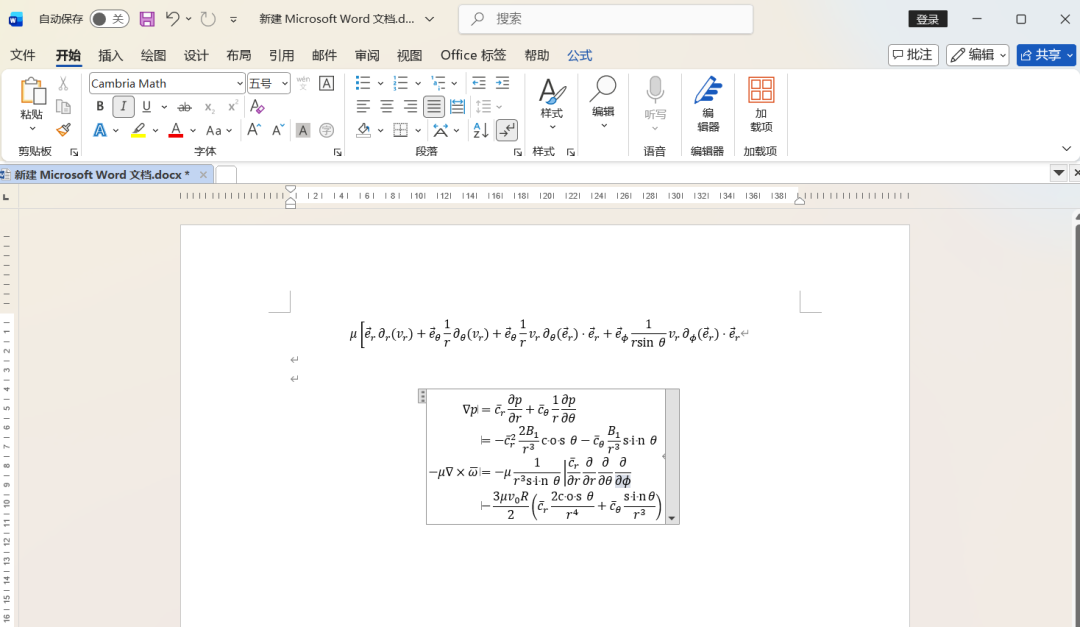
功能很能打:截图OCR、批量OCR、批量文档、二维码、公式识别都有。尤其是对数学公式的识别,准确率相当高,找了一个比较复杂的:
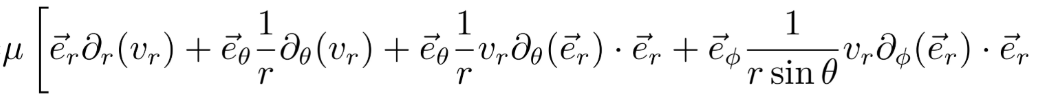
如果觉得还不够复杂,再上一上难度,多加几行:
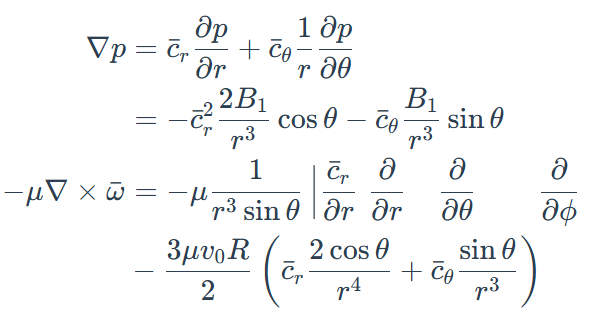
它将公式转换成了LaTeX代码,为了验证它识别的准确程度,我把这些LaTeX代码用一些在线生成网站,比如simpletex.cn,来验证。
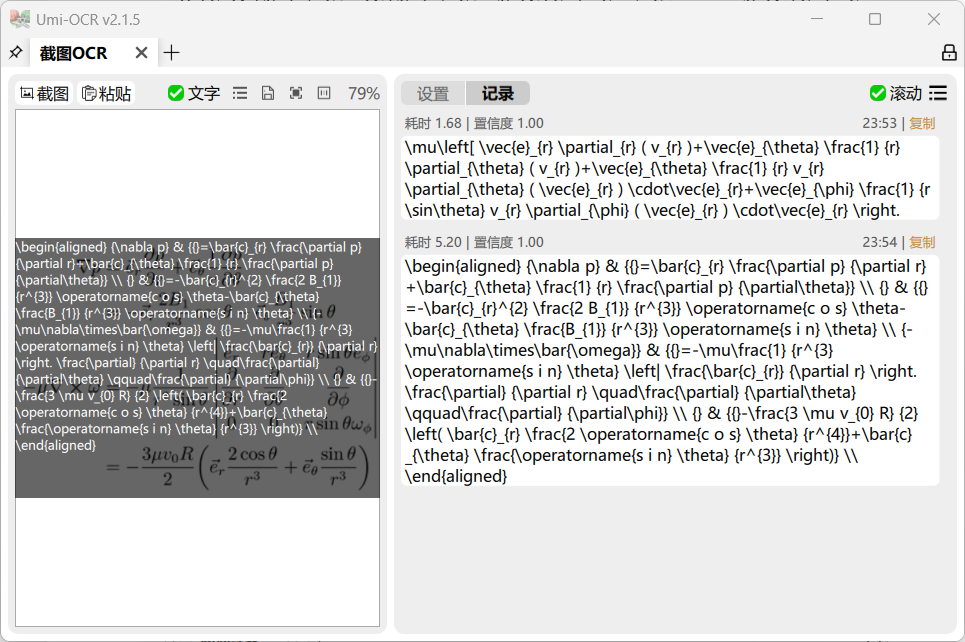
LaTeX代码验证结果:
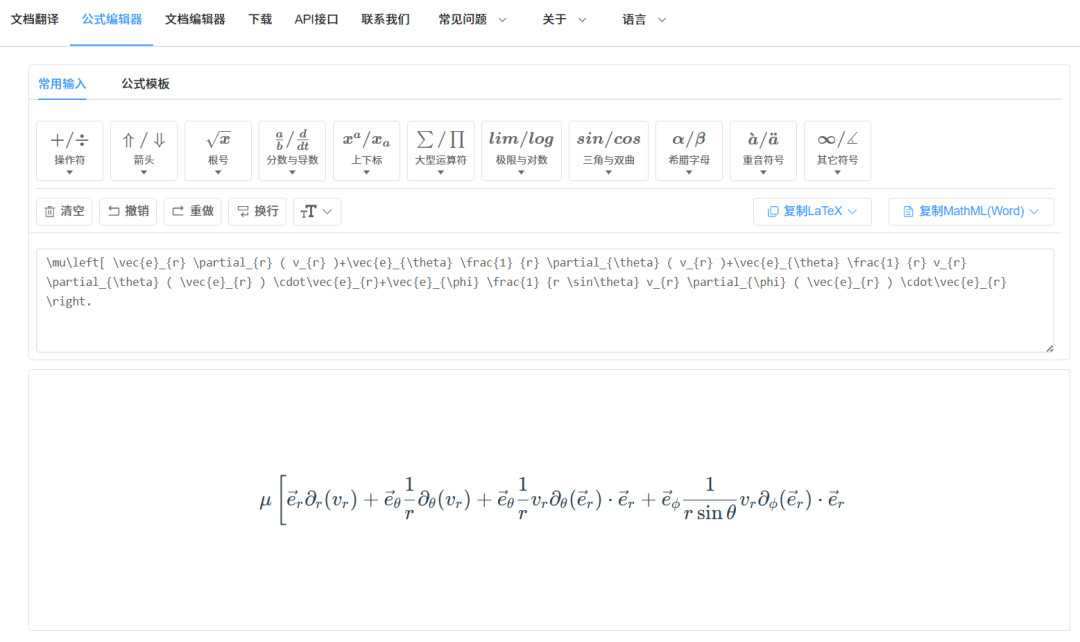

转换成word相应的格式,然后复制进word,可以看到公式的识别准确率相当的高。这对于学生或者科研党,经验编辑公式到头大的小伙伴,可以非常的省心省力了。
软件自带简体中文、繁体中文、英文等多种语言,界面采用标签页设计,用起来很顺手。系统要求是 Windows 7 x64 及以上。三种方式导入图片,识别后还能自动排版。你可以用软件自带的截图工具,也可以直接把图片或文档拖进界面空白处,或者粘贴图片。识别出来的文字支持多种排版格式,整理后阅读体验好很多——这一点很多同类软件都没有。另外,它还能识别 19 种协议的二维码 / 条形码,实用度拉满。
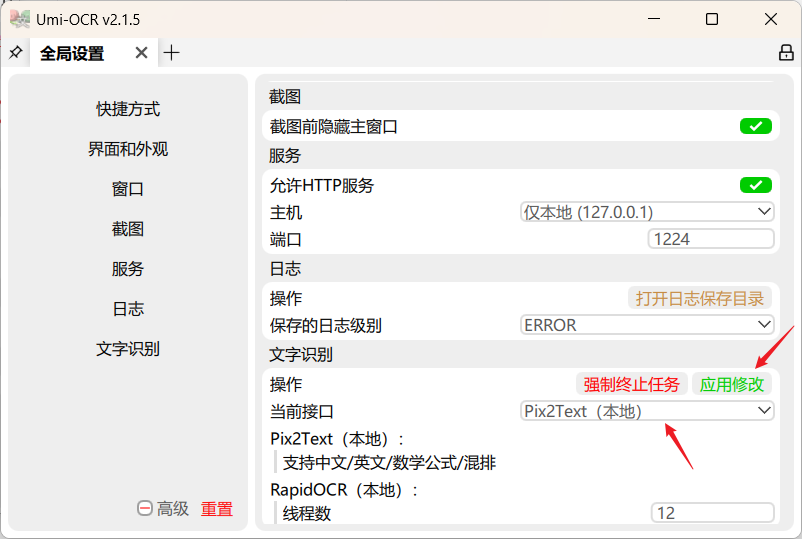
注意,识别数学公式的 OCR 软件不多,Umi-OCR 算一个,不过公式功能需要额外装一个插件。具体步骤:
去项目的GitHub页面(文末有地址)下载公式插件 win7_x64_Pix2Text。
把解压后的文件夹放到UmiOCR-data\plugins 目录下(也就是Umi-OCR的解压目录)。
打开 Umi-OCR,依次点击:全局设置 → 文字识别 → 接口改为 Pix2Text → 应用修改,之后就可以正常使用公式识别了。
一个小建议:识别公式时关掉“启用文字识别”,在设置里建议把“启用文字识别”关掉,这样公式识别的准确率会更高。
Umi-OCR 提供了两个版本,下载后解压就能直接用,绿色免安装。
●Paddle 版:体积大、性能强,但对电脑配置要求也高。
●Rapid 版:体积小,适合配置稍低的电脑。
项目地址:
https://github.com/hiroi-sora/Umi-OCR
插件地址:
https://github.com/hiroi-sora/Umi-OCR_plugins/releases
网盘下载:
https://pan.baidu.com/s/1THMOvdp3DSdGBkknTMKCJw?pwd=heu8 提取码:heu8
https://pan.quark.cn/s/6654d610a40c
